
This is the seventh in our series on common Power BI mistakes.
You can find the other articles here
The relationships between tables are often the biggest source of issues that induce a Power BI-graine (see what I did there?).
Problems occur when relationships are not set up correctly, either when creating your model or adding to it iteratively without properly considering best practice or the final design. Either way, without proper care and attention, you’ll end up with something messy and dysfunctional.
Making mistakes in your relationships can lead to slower queries, incorrect results, vanishing data, tables that won’t join, erroring row-level security (RLS), and broken time intelligence calculations. All of which means you’ll spend a lot of time diagnosing and fixing issues that become ever more complex. At some point, you’ll find yourself asking, “is this relationship worth it?”
The major cause of heartache? Setting a relationship to bi-directional.
Key relationship features: Cardinality and cross-filter direction
Before we move too fast here, let’s slow things down and make sure we’re all on the same page before we dive into something too heavy, too quickly.
(There will be no more bad relationship references, I promise.)
Relationships are briefly described in an earlier post in this series. Here, we’ll look at their two important features: cardinality and cross-filter direction.
The four relationship cardinalities
Cardinality refers to the nature of the join between two tables. There are four relationship cardinalities, visualised in Figure 1 and described below using two imaginary tables A and B:
![]() One-to-One (1:1): In a one-to-one relationship, each row in table A is associated with only one row in table B, and vice versa. Think of it like having a pair of gloves, where each glove will only ever have one corresponding match.
One-to-One (1:1): In a one-to-one relationship, each row in table A is associated with only one row in table B, and vice versa. Think of it like having a pair of gloves, where each glove will only ever have one corresponding match.
![]() One-to-Many (1:*): In a one-to-many relationship, rows in table A can be related to multiple rows in table B. But the rows of table B are only ever associated with one row from table A. Trees have multiple leaves. But a leaf only has one tree.
One-to-Many (1:*): In a one-to-many relationship, rows in table A can be related to multiple rows in table B. But the rows of table B are only ever associated with one row from table A. Trees have multiple leaves. But a leaf only has one tree.
![]() Many-to-One (*:1): The reverse of a one-to-many relationship. The rows of table B are related to only one row in table A, but rows in table A can be joined to multiple rows in table B. (Do we need to go over the trees and leaves again?)
Many-to-One (*:1): The reverse of a one-to-many relationship. The rows of table B are related to only one row in table A, but rows in table A can be joined to multiple rows in table B. (Do we need to go over the trees and leaves again?)
![]() Many-to-Many (*:*): Rows in table A can be linked to multiple rows in table B, and vice versa. Think of groups of friends. Each person can have many friends, and each of those people can belong to many other groups of friends.
Many-to-Many (*:*): Rows in table A can be linked to multiple rows in table B, and vice versa. Think of groups of friends. Each person can have many friends, and each of those people can belong to many other groups of friends.
In Figure 1, there are two rows in the centre of table B that are linked to multiple rows in table A, there is one red, and one blue arrow for each of these, both rows in table A are linked to multiple in table B.

While the cardinality of a relationship is important for your model’s function, it’s often intuitive and much less likely to cause material problems than cross-filter direction.
Cross-filter direction
Cross-filter direction is the direction you wish filters to travel when your visualisations send queries to the model. There are two options:
- Single: Table A passes a filter to table B, but table B cannot filter table A.
Think of this as a one-way street, which you can only drive along in one direction.
- Both: Table A and B can filter each other.
Shockingly, my comparison here is a two-way street, which you can travel along in both directions.
It is the ‘both’ direction filter that we refer to as bi-directional, and should be used with extreme caution.
Problems caused by bi-directional relationships
Bi-directional relationships can lead to all kinds of issues and errors in Power BI. Here’s what to look out for:
Slower queries
Slower queries
On smaller data models, this is unlikely to be much of an issue. But on larger models, bi-directional filtering will slow down DAX query performance due to the extensive evaluation of additional relationships, dependencies and data required after its implementation.
To make this easier to understand, imagine you’ve set up a treasure hunt.
If all clues are sequential and guide people from one location to the next, it’s easy to follow the hunt from clue to clue without diversions.
However, imagine you make the clues dependent on each other – e.g. so solving clue 4 requires info from clue 2 or clue 9 – and throw in the occasional dead end. People would be backtracking all over the place, revisiting previous clues for more information, and having to rule out red herrings.
By making things bi-directional you’ve introduced delays, confusion and inefficiencies. And this is exactly what happens with the introduction of bi-directional relationships in a large data model.
Furthermore, this effect is amplified on many-to-many relationships, which are already slower for queries to navigate, due to the fact that calculations must fully scan both sides of the relationship.
Incorrect results
Incorrect results
There’s an incredible article from SQLBI on this topic which explains this issue in full. If you’d prefer the short version, here are the headlines:
- Bi-directional filtering introduces ambiguity to a model. This means there are multiple paths a query can use to transfer a filter between tables.
- The Vertipaq engine has an algorithm that helps it pick a preferred method for the filters to travel:
- When there is one filter, it will always pick the shortest path.
- When there are multiple filters from different tables, it is possible for multiple paths to be travelled in a single expression.
- When multiple paths are chosen to pass filters between tables, the results of DAX queries become unpredictable and incorrect.
- The more complex your model, and the more of these relationships you have in place, the more difficult it becomes to diagnose where your issue lies.
Vanishing data
Vanishing data
Data may disappear unexpectedly when filters applied across tables do not work as anticipated, often because of missing data or unintended conflicting filters in a related table.
This occurs even if the related table wasn’t directly needed for the query, but was used because the algorithm picked it as the path of least resistance. In this case, the issue arises when there is a disconnect between the source dimension and the end fact table. This disconnect may be due to a lack of linking data in the intermediary dimension, or another filter inadvertently removing it from the query.
Imagine turning on a water hose and pressing the nozzle trigger, expecting water to come out. But nothing happens because you’re unknowingly standing on the hose, blocking the flow. You’re the intermediary stopping your garden from getting a sprinkle.
Difficulties in joining tables
Difficulties in joining tables
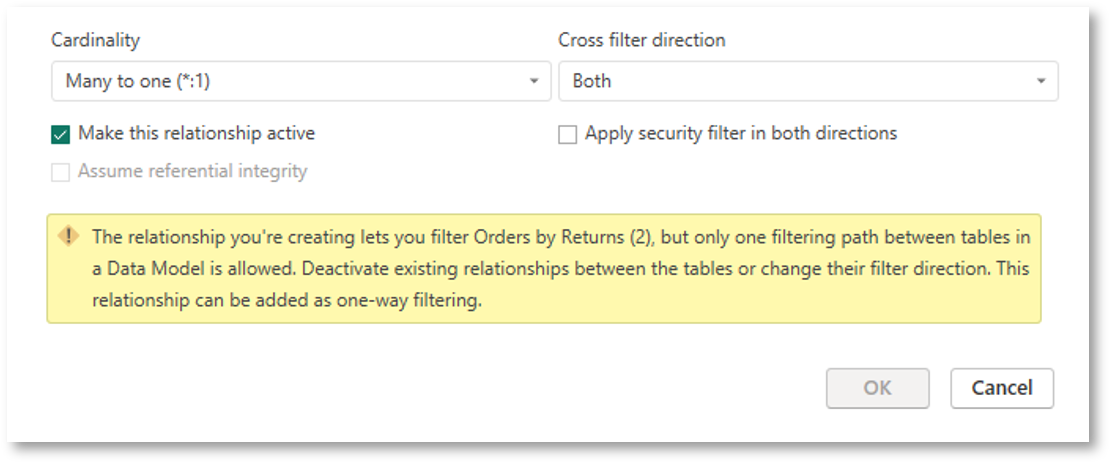
When configuring relationships, Power BI’s built-in checks will prevent you from introducing too much ambiguity, which would leave it unable to decipher the preferred path for filtering. It will also prevent circular relationships which would make it possible for a table to filter itself through other tables.
In both situations, you’ll see a warning like the one shown in Figure 2. The more complex your model, the harder it can be to untie the maze of relationships to resolve this error.
Erroring row-level security
Erroring row-level security
A fundamental principle of row-level security (RLS) – used to restrict data access for specific users – is that it has a single routeway to apply its filters to your model’s tables. Bi-directional relationships can cause errors by introducing multiple routeways for filtering to be applied.
If you’re using RLS, one bi-directional relationship will usually be fine. Depending on the visibility you wish people to have, you may just need to play around with the ‘Apply security filter in both directions’ setting seen in Figure 2, to ensure your security is being applied correctly.
However, if you were to introduce a second bi-directional relationship that somehow didn’t break any ambiguity or circular rules, you are increasing the likelihood of running into an RLS error and this will likely be due to ambiguous filter paths.
Broken time intelligence
Broken time intelligence
If you’re using DAX time intelligence functions and the specific date column named in the function has a bi-directional relationship linked to it, you’ll get an error message like the one in Figure 3.
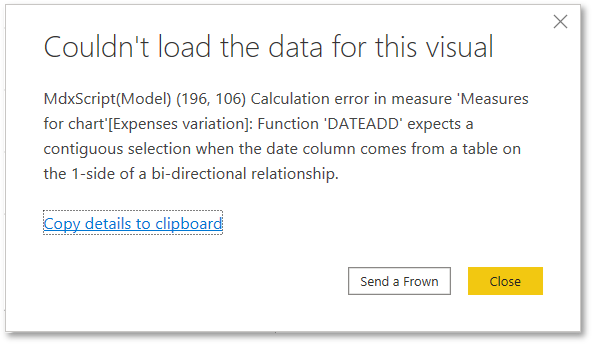
When I received this error, the relationship was to a different fact table than the one used for my calculations, and my dates were definitely contiguous.
This piqued my interest. This article by Chris Webb suggests that a similar error he witnessed was actually a deliberate design feature built to prevent calculations returning erroneous results. This, to me, points to another attempt by Microsoft to prevent model ambiguity.
This error is not well documented, but that may be because it’s fairly uncommon since Microsoft changed the default relationship direction to Single.
So, what can you do to avoid the pain and heartache
The exact solution needed will be driven by the problem you’re trying to solve, but here are some options you should explore.
Use single-direction relationships
Use single-direction relationships
It seems so simple, because it is. If you make this your mantra, you will explore every possibility to maintain its integrity – and that of your model.
Use Measures
Use Measures
The direction of a relationship can be changed in a DAX measure using CROSSFILTER this is a powerful way to ensure your model does not become ambiguous, whilst only changing the context of the relationship when it’s needed.
Explore Alternative Data Modelling Techniques
Explore Alternative Data Modelling Techniques
Sometimes you just need to take a step back from the existing model, and re-evaluate its design. For instance, if the model is not a Star Schema, making it so could solve your problem, and so could changing the granularity of a table.
Disable “Autodetect new relationships after data is loaded”
Disable “Autodetect new relationships after data is loaded”
This setting (shown in Figure 4) is there for convenience, but it definitely does more harm than good. With it enabled you’ll have incorrect and unwanted relationships, slower initial data loading, less control over your model and you may occasionally find a relationship you’ve already removed has been recreated. Lastly, you’ll miss opportunities for learning a vital modelling skill in understanding how relationships work.
It’s truly perplexing that this is enabled by default AND that you cannot switch it off globally, it must be done in each new file.
Wrapping Up
So to avoid heartache and messy breakups (AKA hours spent diagnosing and fixing problems caused by bi-directional relationships), stay away from this relationship type except where really warranted.
You’ve now had a complete (at the time of writing) rundown of why you should only use them with very good reason (syncing slicers doesn’t count), extreme caution, and after first exploring all other methods to solve your problem. Luckily, I’ve never come across a relationship need that couldn’t be solved with a bit of creative modelling or DAX wizardry.


